Testing Jetstream Configs
Validation via Continuous Integration (CI)
Configurations for Jetstream experiments get added by opening a pull-request in the metric-hub repository. Continuous Integration (CI) automatically runs checks to validate that the syntax and SQL definitions of the new or updated configuration files is correct. These checks only run for pull-requests that are opened from a branch that was pushed to the metric-hub repository. For pull-requests based on forks only some checks will run.
Pull-requests that pass the CI validation can be automatically merged without requiring an external review.
Local validation
To locally iterate and validate Jetstream configurations, the Jetstream tooling needs to be installed:
pip install mozilla-jetstream
Once installed, local config files can be valided using the jetstream validate_config command:
jetstream validate_config /local/path/to/config/file.toml
In case changes have been made to outcomes, defaults or metric definitions it is possible to specify a local metric-hub directory to be used for validation:
jetstream validate_config /local/path/to/config/file.toml --config_repos=/path/to/metric-hub
Jetstream previews
When iterating on configurations, it is sometimes useful to get a preview of what computed data on the final dashboard would look like. Previews are computed on a data sample in order to reduce cost and speed up the analysis. Preview data should not be used to draw any conclusions on the outcome of an experiment. It should only be used to validate configurations.
To generate previews, install the Jetstream CLI tooling locally:
pip install mozilla-jetstream
Authenticate to GCP:
gcloud auth login --update-adc
And set the project to mozdata
gcloud config set project mozdata
This is the default project where preview data will be temporarily be stored in. It is also possible to set this project to a personal sandbox project, or any other project with write permissions.
Preview data can be generated using the jetstream preview command:
jetstream preview --help
Usage: jetstream preview [OPTIONS]
Create a preview for a specific experiment based on a subset of data.
Options:
--project_id, --project-id TEXT
Project to write to (default: mozdata)
--dataset_id, --dataset-id TEXT
Dataset to write to (default: tmp)
--start_date, --start-date YYYY-MM-DD
Date for which project should be started to
get analyzed. Default: current date - 3 days
--end_date, --end-date YYYY-MM-DD
Date for which project should be stop to get
analyzed. Default: current date
--num-days, --num-days INTEGER Number of days for which the project be
analyzed. Default: 3
--experiment_slug, --experiment-slug TEXT
Experimenter or Normandy slug of the
experiment to (re)run analysis for
--config_file, --config-file FILENAME
--config_repos, --config-repos TEXT
URLs to public repos with configs
--private_config_repos, --private-config-repos TEXT
URLs to private repos with configs
--analysis_periods, --analysis-periods ANALYSISPERIOD
Analysis periods to run analysis for.
--sql-output-dir, --sql_output_dir OUTDIR
Write generated SQL to given directory
--platform TEXT Platform/app to run analysis for. If not
specified, use Experimenter API to determine
plaftorm [required]
--generate-population, --generate_population
Generate a random population sample based on
the provided population size. Useful if
enrollment hasn't happened yet
--population-sample-size, --population_sample_size INTEGER
Generated population sample size. Only used
when `--generate-population` is specified.
Use floats to specify population sizes in
percent, e.g 0.01 == 1% of clients
--enrollment_period, --enrollment-period INTEGER
Numer of days used as enrollment period when
generating population.
--help Show this message and exit.
By default the preview runs Hetstream on a 3 day analysis window on a population sample of 1%.
These default parameters can be overwritten when invoking jetstream preview.
The resulting data artifacts get written into the mozdata.tmp dataset by default, which is configured to delete data after 7 days. Anyone at Mozilla has permissions to write to this dataset.
To generate a preview on a 10% sample for an existing experiment on Firefox iOS run:
jetstream preview \
--experiment_slug=ios-search-bar-placement-impact-assessment \
--start_date=2022-08-01 \
--platform=firefox_ios \
--population-sample-size=10
Jetstream Preview fetches experiment information from the Experimenter API.
In some cases a preview might need to be generated for experiments that haven't been launched yet or that haven't seen any enrollments. For these experiments a random population sample can be generated when specifying --generate-population that will be considered as the clients that enrolled:
jetstream preview \
--config_file=/path/to/local/config.toml \
--start_date=2023-01-01 \
--platform=firefox_deskop \
--generate-population \
--population-sample-size=1
Once preview data has been computed, a link to a Looker dashboard will be printed where data for each metric and statistic is visualized:
A preview is available at: https://mozilla.cloud.looker.com/dashboards/experimentation::jetstream_preview?Project='mozdata'&Dataset='tmp'&Slug='ios_search_bar_placement_impact_assessment'
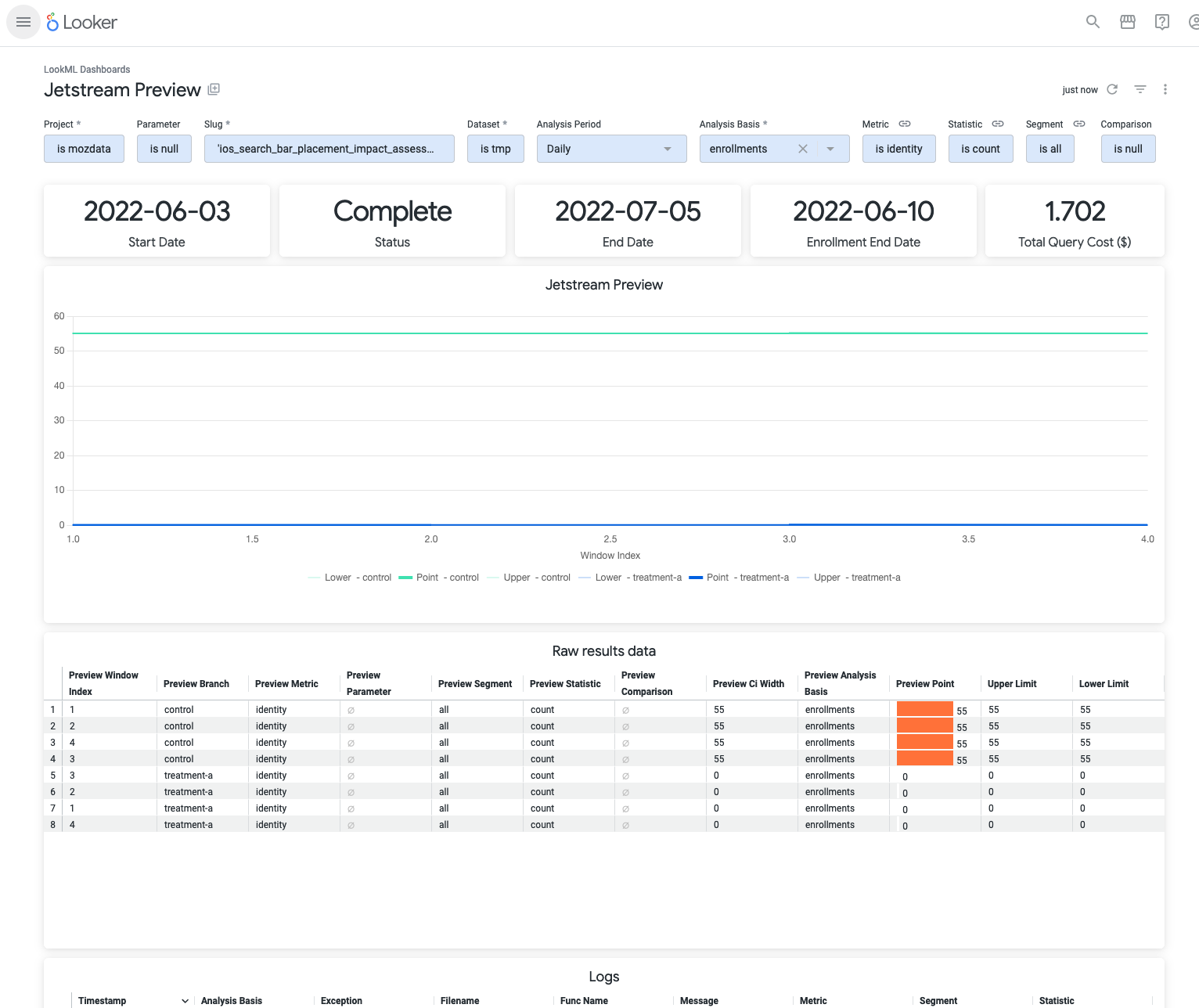
The dashboard shows the computed statistics for each metric in a graph, raw results as they show up in the BigQuery table as well as logs that were written during the analysis. Some additional metadata about the experiment is shown at the top. Also a cost estimate is provided. The estimate is based on the sampled data, as well as a subset of analyses periods and days. The final cost will be much higher.
The preview data gets written into the tmp dataset in the mozdata project by default. Data written to this dataset gets automatically removed after 7 days.